library(delaydiscount)
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, unionThe simulate_dataset function can be used to simulate
data from the hierarchical linearized hyperbolic model.
The hierarchical linearized hyperboloid model works as follows.
The hyperbolic model for the discounting curve is . However, actual discounting rates reported by subjects may not fit this curve. Actual discounting proportions are assumed to be between 0 and 1, exclusive. They are transformed from the scale to a scale by the function .
The model discounting curve with the transformation applied is . The transformed curve provides a mean structure for the data, conditional on the subject’s parameter.
We assume that the transformed observed indifference point will follow the model
where , is an index for subject, an index for time point, and is an index for group/condition.
, where is the population mean of the for subjects in group , and is the number of time points observed for each subject.
The model is hierarchical, as the parameter for each subject within a group is assumed to be a realization from a normal distribution with some population mean for its subjects, and variance , i.e. the variance is constant across subjects, across groups.
A call to simulate_dataset is shown below.
set.seed(8678)
sim_data <- simulate_dataset(groups = c("EFT", "HIT", "NCC"),
num_subj = c(120, 142, 172),
time_points = c(30, 90, 180, 365, 1095, 1825, 3650),
mean_ln_k = c(-6.877, -5.861, -6.078),
sigma_sq = 1.978, g = 10.407)The groups vector gives the name of the groups in the
simulated study.
The num_subj vector gives the sample size for each
group.
The time_points vector gives the surveyed delay
lengths.
The mean_ln_k vector gives the group mean
hyperparameters.
The value sigma_sq gives the parameter
,
which represents the conditional variance of an observed transformed
indifference point
given the subject’s
parameter.
The value g gives the ratio of the variance subject
parameter to the conditional variance of the least squares (on the
transformed scale) estimator of a subject’s
parameter given the true
.
The result is that the true
parameters have variance
.
(Recall
is the length of the time_points vector.)
The data frame output by sim_data can be analyzed using
our analysis methods. In particular, prepare_data_frame and
jb_rule_check are ready to be run on the data frame.
However, dd_hyperbolic_model and
get_subj_est_ln_k will still need to be run on the output
from prepare_data_frame.
# These methods can be run on the output from simulate_dataset
prep_data <- prepare_data_frame(sim_data)
rule_check_results <- jb_rule_check(sim_data)
# These methods need to be run on the output from prepare_data_frame
subj_est_ln_k <- get_subj_est_ln_k(prep_data)
sim_model <- dd_hyperbolic_model(prep_data)The output from simulate_dataset has one observation per
simulated subject per delay for which an indifference point was
observed. It has columns subj, true_ln_k,
group, delay, and indiff.
The columns other than true_ln_k are necessary to run
the analysis function on the dataset. The subj column
identifies the subject, the group column identifies the
group, the delay column identifies the length of time for
which the observed indifference point is measured, and the
indiff column contains the subject’s indifference point for
the delay expressed as a proportion of the maximum reward.
The true_ln_k column contains the true
parameter of the subject which the observation corresponds to. This can
be used to compare estimates of the subject
parameters with the true values.
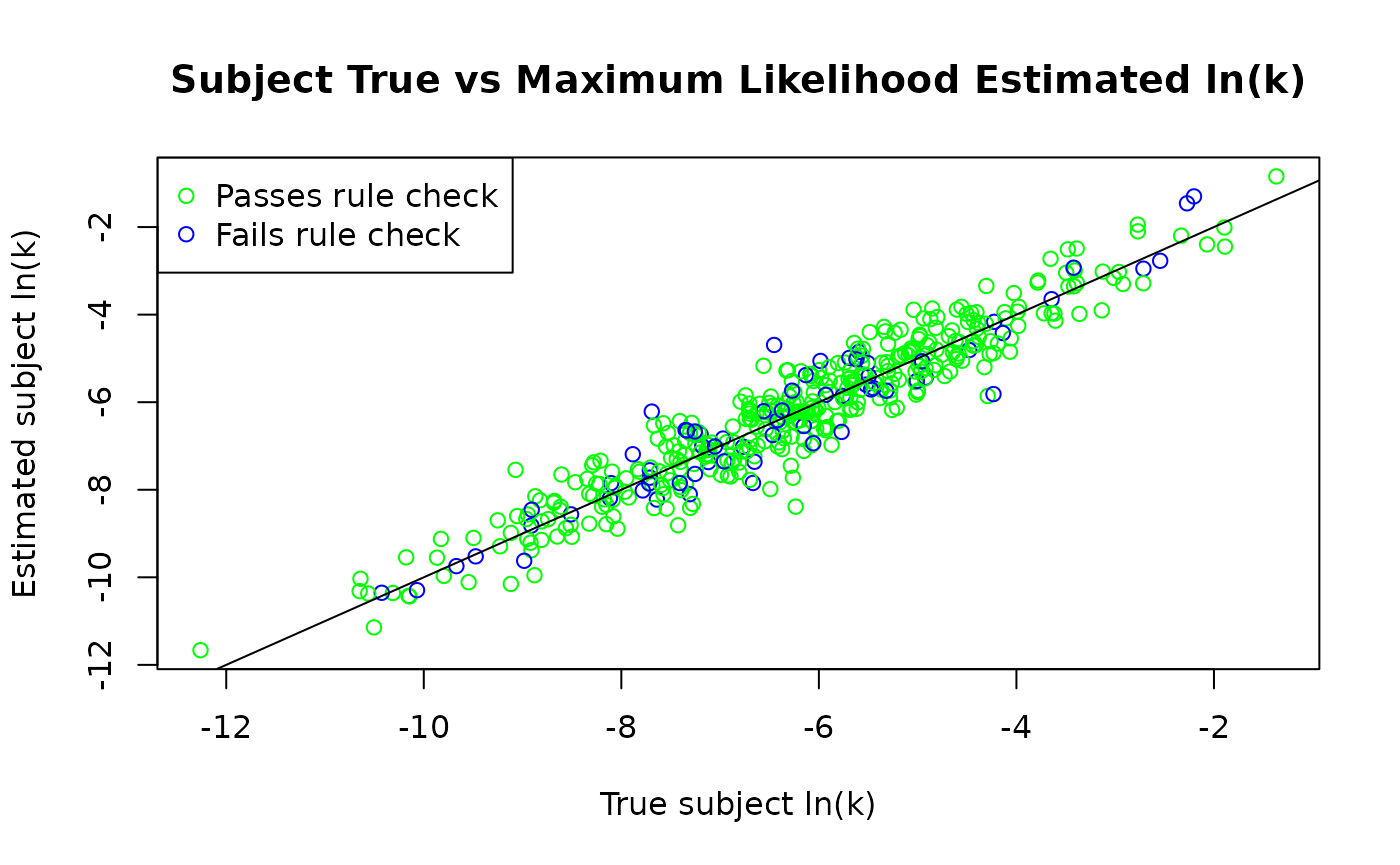
For example, the following code produces a plot of the true vs estimated subject parameters, with points colored by rule check result.
# Get a data frame consisting of one observation per subject, containing each
# subject's true ln(k)
subj_true_ln_k <- sim_data %>%
select(subj, true_ln_k, group) %>%
unique()
# Merge the data frames containing the true subject ln_k values, estimated
# subject ln_k values, and rule check results.
subj_ln_k_comp <- merge(subj_est_ln_k, subj_true_ln_k)
subj_ln_k_comp_wrc <- merge(subj_ln_k_comp, rule_check_results)
# Get the overall rule check result for each subject
subj_ln_k_comp_wrc$rc_pass <- subj_ln_k_comp_wrc$C1 & subj_ln_k_comp_wrc$C2
# Make a plot showing true vs estimated ln(k) for each subject,
# coloring the points based on whether or not the corresponding subject
# passed the rule check.
plot(x = subj_ln_k_comp_wrc$true_ln_k, y = subj_ln_k_comp_wrc$ln_k,
col = ifelse(subj_ln_k_comp_wrc$rc_pass, "green", "blue"),
main = "Subject True vs Maximum Likelihood Estimated ln(k)",
xlab = "True subject ln(k)", ylab = "Estimated subject ln(k)")
abline(a=0, b=1)
legend("topleft",
legend = c(
"Passes rule check",
"Fails rule check"),
col = c("green", "blue"), pch = 1)